Anyhow, I've decided that key points to express (and there are so many, all mutual forward references, which is why picking the ones with which to open is such a tangle) include:
Superficially this seems like an unlikely article of faith to add to work queues, but the two are actually very intertwined. Producer / consumer queueing offers a very convenient way for the two styles of cores to transfer work back and forth at a fine granularity while preserving enough context to group and dispatch it efficiently. They are the very mechanism which breaks the batch oriented feed-forward pipeline into a multi-directional state machine and one aspect of that change allows work to move between states serviced on compute cores and on conventional cores.
Commodity operating systems still retain the design principles developed when processor cycles were scarce and RAM was precious. These out-dated principles have led to performance/functionality trade-offs that are no longer needed or required; I have found that, far from impeding performance, features such as safety, consistency and energy-efficiency can often be added while improving performance over existing systems.Too bad the talk itself is at 4:15PM on my birthday. Maybe I'll end up going anyways.
Personally, I think the biggest challenge remaining still is to articulate the framing. I really don't like the instinctive pigeon-holing that we're trying to talk about next generation GPU++ style designs and that everything has to be scrutinized and policed carefully for its negative impact on graphics. I don't care about graphics! That's intentionally a bit of an overstatement, but the fundamental point to me is actually about CPU evolution: the combination of a trend towards compute-dense cores (be they GPU, Niagara, Larrabee, Ageia, or whatever style) that intrinsically offer an order of magnitude compute win over CPUs in the same deisgn budget and the universality of multi-core CPUs means that the "right" future CPU will be heterogeneous-- a number of conventional fat cores (single threaded / ILP performance isn't giving up its mindshare any time soon, whether or not one accepts that it truly matters technically) and a number of compute-maximizing cores.
It's really exactly the same argument as for on-chip FPUs or SSE. There's certainly always other things, even if only a tiny bit of extra caching, that could be eked out with that die area / transistor budget, but they're useful enough for applications that are important enough and the opportunity cost is small enough that they're universal on modern CPUs. I claim the same is on the cusp of being true for FLOP-dense cores and that the ubiquitity advantage of making them part of the nominal notion of CPU and ability to co-opt CPU - compute core coordination, scheduling, and communication into the ISA is huge. That's really basically my claim, along with a bunch of more concrete opportunities to use that architecture to tweak / change the givens of today's CPU plus compute accelerator model to recover a lot of the flexibility, expressiveness, and porting pain researchers currently incur trying to do anything beyond toy programming of compute cores. Even without those improvements though, I think there's a huge insight (though calling it an insight when it seems so obvious to me feels unjustified) in just recognizing that pulling in a compute core as a first class aspect of the concept of CPU is a huge opportunity. And, at the same time, it's really not a radically different hardware change than continuing to bulk up the SSE units, make them more programmable, and devote a hardware thread to them.
He followed the talk with an NDA-concealed much more concrete talk that included a lot of lively debate and discussion. And nearly all the faculty who have offices on the third floor. Unfortunately, from my perspective, we got bogged down in the nitty gritty microarchitectural details of buses, cache organizations, etc. for a long time and the higher level architectural pieces got short shrift and the OS / applications level pieces were extremely rushed. It also makes it challenging to write more concrete my impressions of the public talk without worrying about compartmentalizing the private content.
And nobody paid any attention to hybrid, even though they immediately admitted it was the way to go for making a system like this practical. Grr.
Unfortunately, I've also successfully persuaded him (and more importantly myself) that we need a Shader Model 4.0 interpreter as the first stage in our testbed. It's nice to have something concrete to develop, but in many ways I would rather continue to focus on maturing our ideas and writing before jumping into coding.
Reminder-- our off again, on again relationship with Gates 392 is on again this coming Tuesday. Jeff will tell us something that most likely will make us all question whether our jobs and research are morally fulfilling and Kayvon will feed us something to appropriately celebrate the mutual Texan pride he and Jeff share.
Unfortunately, the paper totally derailed the thesis topic pursuit and I was sluggish about recapturing my mindset. Conveniently, perhaps, Kathi decided to encourage me along by putting my registration on hold without warning at the start of December. That was a bit of a surprise, and turned out to be punishment for TAing with Kayvon thus also getting snagged while Mike and Daniel squeaked through. It effectively got my attention though, and Pat's. We had a series of frustrating conversations around topics I'd articulated and what feels like just an impedence mismatch in the way we approach things and understand words like claims, assumptions, hypothesis, etc. Ultimately we not only managed to understand each other, but he managed to talk me into a much more gradiose vision that I'd laid out and dismissed as too big and, more importantly, too much an argument over vision instead of something that could be demonstrated. It even converged nicely with Kayvon's new interests, so we've gotten the band back together, so to speak. Now I just need time to think and time to work. Hopefully that will be easier once the admissions committee work is done in a month. And we revise the ray tracing paper for its camera-ready deadline in two weeks.
9 June 2006:
Therefore, I've organized my thinking around potential thesis titles and accompanying premises. Pat and I spent a while yesterday discussing (arguing about) our perspectives and I have four to four and a half quite plausible topics (the half isn't quite so fully baked in that it's based on shading work into which I haven't yet dug deeply enough to be confident there's an answer, plus I go back and forth on how much I actually care personally about shading) and two titles that expressly are not worth pursuing (both overlap with my 'good' titles in the critical places and are ill-posed in other aspects).
The good news is four and a half valid thesis topics is plenty. The bad news is that they cover a wide scope and are sufficiently different than focusing on one means putting aside projects I really want to see completed. The other bad news is that, naturally, the most deep / visionary topics are also the ones least liable to actually be useful and involving the most hand-waving and simplifications. By and large, that can be what one expects from an academic thesis, but a piece of me rebels and argues that vision and hand-waving are critical to have framing the choice of projects and topics, but that the projects and topics themselves should stand on their own as a valuable incremental contributions even if the vision never comes to pass. This is tied to my conviction that it's always better to hire someone who can get his hands dirty and ship code than someone full of vision who always hand-waves the implementation details and thus produces projects that never actually deliver or work quite right. I wouldn't trust a bridge builder who pitched an amazing span but admitted he had no idea how to come up with materials that would actually tolerate the induced strain. You can argue that the vision will prompt lesser minds to solve the engineering details, but I don't buy it. I 'invent' an unlimited number of things that just aren't possible and if someone else later comes along and makes them possible, he deserves the credit, not me. I argue the same applies to at least my own thesis or I'll never be satisfied. This is also why I came to believe academia is a bad place for me, though I may be good for it in the same way that eating one's brussel sprouts is good for one.
26 May 2006:
I'd like to say that all of those rumours are massively overblown. They're spun around kernels of reality, but in many ways developing for Cell is just like developing for a chip multiprocessor (or any other SMP). If you don't want to involve the PPE core in your compute kernels (and you certainly don't need to) then there's write-once support code to spin up the 8 SPEs (or however many you want) and launch your apps. You write it once based on either the sample code or the tutorial and never look back. Occasionally, if your workload needs it, you add some very simple message passing for SPEs to signal the PPE when they need to be sent more work and the PPE to respond when more work is sent. Anyone who has ever written a work queue or used a socket for signalling can do this three days dead. It's no different for Cell than via Win32 events or BSD sockets. The APIs just have their own function names. Hooray.
Okay, so now you've gotten your SPE up and running. To be precise, just like starting a thread on any other OS, you've issued a library / system call that took a chunk of code (the ELF binary compiled for the SPE), an entry point (thread main), a void * with initial arguments, and some unimportant optional flags. What about the SPE code? You take gcc and hand it vanilla C code. Or, you take xlc and hand it vanilla C code if you think xlc is more elite than gcc (we don't. Other people around here do. It seems to vary according to personal taste and application). Okay, so it's not quite that easy. You can transparently use stack allocated memory and static / global arrays or objects that are small enough to fit in local store. You cannot transparently malloc huge chunks of memory or dereference pointers to large, system memory backed regions. However, you can mechanically convert every dereference of your big data structures into synchronous DMA and you'll come out with working code. If you're writing from scratch or have anything resembling an accessor function, this is near trivial. The DMA builtins actually take system memory pointers as their argument without any translation or anything. We hit this point with the ray tracer after a few days' messing around. And a major portion of that time was browsing reference material and one-time cobbling together of a Makefile with the correct include paths and what-not to run the cross-compile toolchain.
That's it. Porting in a nutshell (I know, why is it in a nutshell and how do you get it out? Don't ask). But, but, but, you splutter, what about having to restructure your whole application? What about fitting your code + stack + data in 256KB? You don't have to restructure anything. You always can run on the PPE. If you want performance from the SPEs, you will have to multithread at least part of your application into at least 8 threads (or however many SPEs you want to use). However, if you want performance with any chip including current conventional CPUs, you have to multithread the computationally dense portion of your application. Multithreading for Cell isn't intrinsically different from multithreading for a "normal" CPU. So, while I'm happy to grant that having to multithread your code to get performance can be a pain, it's no special barrier unqiue to Cell. Now, as for fitting in 256KB, well, that's a ton of space. I'm clearly a child of the wrong era and it's about to be very clear, but once all your application data is excluded (it lives in system memory, not local store), 256KB is great! With four byte instructions (I have no idea what Cell's instruction width is, but 4 bytes is a fine proxy), splitting LS half and half instruction and data gets you 32K static instructions which is huge for a computational kernel. Moreover, dynamic linking just plain isn't hard and it naturally combines with overlays to allow arbitrarily large code executed in a fixed amount of space. That's too hard for you? Luckily only one guy needs to write it for Cell and we can all use it. However, that's really more for the future. The whole raycasting portion of our code compiles down to 60KB or so. Similarly, the stack size limitation just doesn't seem interesting to me. I've probably spent too long writing kernel code and other specialized code, but if you need more than 4KB, or maybe a whole 16KB, of stack space then you're not writing for performance. And if you don't want performance, get that code back on the PPE where it won't bother us. All told, in a fairly pessimistic scenario, you're left with 128KB or 96KB of space for data. If you're just replacing pointer dereferences with DMA that's tons of space. Actually, there's 2KB of register file (128 x 4-word wide) and that's probably enough.
What's that? Replacing pointer dereferences with DMA is unusuably slow? So it is. If you grant my conservative assessment that there's 96KB of LS available for data then just use it as a simple cache. It takes a day or so to code a simple direct mapped cache (remember, we're discussing how hard it is to get code up and running on Cell. By this point, the naive code was working in the last paragraph and we're just looking for any cheap extra boost) and it's a tiny amount of extra instructions. That 96KB of code is 6x the L1 on a Pentium 4 (and you've got 2KB of registers where the Pentium 4 has to use its L1 to compensate for its tiny handful of registers). So, in exchange for another day of porting (we're almost up to 1 week for 1 grad student who's easily distracted and a little lazy) not only have you ported your app, you've smoothed out the most unreasonable shortcut you used to get the port working.
If your application doesn't benefit from caching then the bad news is implementing the simple cache won't help you on Cell. However, the worse news is that your execution time on normal CPUs is already as bad as the synchronous DMA version on Cell. Or else, you have some a priori knowledge of your algorithm that lets you prefetch or do some other contortions on normal CPUs to get performance up. In that case, there's some good news-- there are no games on the SPE-- you just tell the DMA controller what you want it to prefetch and it goes and does it. No funny "we may or may not honour the hint" prefetch or non-temporal write instructions and no irritating hardware memory hierarchy working to thwart you. Programmer say, Cell do. Seriously, if you are lucky enough to have one of the workloads whose access pattern is structured then Cell is just great. Rather than hinting (or tricking) a CPU into doing the right thing to get bandwidth to memory, you lay it out explicitly for the DMA controller and it happens.
Anyhow, bottom line, we had a working port of the ray tracer in a couple of days and a reasonable starting point to beging analysis and optimization within about a week. The development environment / tool chain is fine (it's not *awesome*, but it's gcc). And the code is pretty much normal multithreaded C code with some funny Cell specific calls instead of pthread or Win32 calls for the scaffolding. So stop the fear mongering. Thanks.
22 May 2006:
16 May 2006:
I ran a pre-checkin round of performance tests (with lazy disabled, but present in the code) and confirmed that the builder didn't get any slower (except for the cbox which is trivial enough that the overhead of the initial lazy root shows up as a fraction of a millisecond) and the ray casting times are actually faster (because of short circuiting on empty leaves). More rigourous numbers when I have more time.
Oh, that's reassuring. For a few minutes I thought I'd made the code slower somehow. Then I realized I wasn't testing 1024x1024 images and 256x256 images don't get as many rays per second (presumably from high packet inefficiency / reduced packet coherence). Whew.
They assumed that no matter what, the programmer has to take the hit of rewriting his monolithic code to be multi-core aware, but then tried to qualitatively assess the programmability of various systems with "general purpose multicore" at the maximum of ease. It certainly has seemed to me like once you suck up the hit of multi-threading your program, porting it to Cell's pretty straightforward. Other than the lack of an i-cache, the constrained LS is not big deal. Our software managed cache for the raytracer is both low overhead and extremely effective. There were also some weird claims about the available GFLOPS of various systems and nothing was consistently normalized either to per-core or per-chip. Ah well.
The most awkward part is that I'm still not sure what concretely they're proposing. Certain minor memory system changes are clear, but they've already demonstrated that they only get about a 20% boost from that, which isn't nearly enough to be competitive. There's some implicit assumption that general purpose CPU vendors will tack on lots of extra FPUs anyhow, so it's just a question of getting those fed. That's certainly not consistent with what I've seen to date (except in special purpose CPUs). And I don't know the cost. Since everything was per-core it's hard to get a sense of how many SPE-like things versus how many symmetric cores I could get on a given chip. Jayanth suggested a factor of 2 or 3 difference which makes me question the worth of the balance. I don't see what I get in exchange for having half or a third as many cores other than a branch predictor and a hardware cache. The branch predictor's not huge (and adding simple branch prediction to an SPE would be a trivial feature) and my software managed cache both has much more control (good for sophisticated programmers) and minimal performance impact (compared to a theoretical perfect full speed hardware cache the ray tracer runs at 94.5% speed). Clock for clock we're right around or over the point where clock for clock each SPE is faster than a Pentium 4 so cutting the number of SPEs by a factor of 2-3 in exchange for Pentium 4 cores is clearly a bad trade for us.
The most baffling part for me was the repeated statement (it wasn't even a claim, everyone seemed to take it as obvious) that Cell is a streaming processor. I don't get it. If a multicore CPU is threaded (or at least not streaming) then Cell is threaded (or at least not streaming). Fundamentally, I can have one SPE decompress my video, another deinterlace it, etc. and I can't do that on any streaming architecture I know. Certainly I can make all the SPEs work together in a streaming fashion, but that's true of any threaded architecture. The models are inclusive in that direction. But not in the other and Cell pretty clearly is threaded in the sense that it has 9 completely isolated and independent threads of execution that are available. Moreover, the memory system (and the DMA controller) allows arbitrary memory access patterns (with sufficient foreknowledge) instead of the a priori access patterns streaming demands. The whole concept of implementing a software managed cache in the heart of the inner loop of the raytracer should make that clear. (Of course, the fact that you can software pipeline among the SPEs should also make that clear). This Cell = streaming meme is very strange.
15 May 2006:
Okay, bizarrely, that turns out to be completely untrue. When I rewrote the code to do the test at the bottom of refineNode() before recurring, all the big scenes got nontrivially slower (tens of milliseconds slower). That doesn't make much sense since there should exactly the same amount of work per node (other than the root) still and near the bottom of the tree, we should save recursion. I guess the code may have gotton a tiny bit more branchy. Still, that's weird.
Bottom line: The infrastructure for the lazy builder doesn't impair the offline builder.
8 May 2006:
I'd sort of settled into 4 bundles per packet (16 ray packets) by default when experimenting with large packets. Because of awkwardness in my sampler, I'm stuck with power of two sized packets, so I can't explore the space too densely without fixing the sampler. Instead, I ran through the robots, kitchen, and bunny with 2, 4, and 8 bundles per packet. For the kitchen and bunny, 4 was definitely the highest point. For the robots, 8 was about 3% faster. When I tried them at 16 though, performance fell back down to the same level as 4. So, I guess I'll stick with 4 bundle packets for now.
Sad. I just went and tried the current version of our brook kd-tree code on the various boards in the lab and it doesn't work at all. The ATI board just goes into an infinite loop and the NV board produces the same sorts of artifacts as the board I have. I'm so glad I don't care very much about GPUs.
However, even once I correct the timing, the rasterization numbers are pretty good. They're pretty much a direct function of the number of triangles in the scene (no surprise since I shove all the primitives in a vertex array and dump them on the board). I've done some timing with and without GL_LIGHTING enabled. Without it, the cbox manages over 1350 fps down to 95 fps for the kitchen. With lighting, cbox only drops to 1310 fps, but the kitchen drops to 64 fps. Those are all at 1024x1024. Messing around, performance is clearly dependent on resolution, but not in any simple way. 512x512 looks to be a bit of a sweet spot for this particularly board.
5 May 2006:
First, build times (release build, single run, no avg, no nothing). Note that 'build time' is the entire time it takes to run the constructor including packing the triangles into primitives, building the tree, and building all the precomputed triangle intersection numbers:
Now, raycasting times for 1024x1024 images, 4 bundle packets:
CPU Shading times are pretty awful, but then that's no surprise. I haven't done careful measurements against even the Brook shading code yet, though.
P.S. If you're curious, my X800XT can rasterize and do direct diffuse lighting at more than 1000 fps (equivalent to casting 1 GRays/s). That's fast enough that I feel obligated to double check the timing code, but it was accurate on the X300.
25 April 2006:
7 March 2006:
Of course, the bad news is that I haven't done any of it. Or seemingly much of anything else. It distinctly feels like the last few weeks have been juggling and treading water. It's already time to synthesize the new things we've read about and the ideas we have in flight and figure out what we're really going to do. I think I should just push forward with a rasterization based system and to heck with trying to fit it nicely into the existing raytracing framework. Oh, and course, ATI still can't release a driver that works. We finally have one that returns a value other than zero for occlusion queries, but the full blown raytracer generates either impressively wrong results or infinite loops depending on configuration. I love the choice of fast but hopelessly broken versus unusably slow. Maybe someday we'll finally get that Cell and be a the mercy of a new vendor's software system (without even a mature API that can supposedly be used).
9 February 2006:
For reference, here's the reduction in packet intersections with perfect mailboxing. Mailboxing has a bigger relative benefit with packets than scalar intersection because the packets visit more a few more nodes. This is with 256x256 scenes.
Given my belief that intersection is roughly half of the total ray casting time, I must be doing something wrong not to be able to capture any speedup on the bunny or robots.
2 February 2006:
It was good to get something down as a starting point (though really that's a distillation of a series of whiteboard "implementations" and discussions Tim and I had) and I've started accumulating additional slides and descriptions to have around for future presentations.
Now I should actually get more organized about writing directed code.
20 January 2006:
19 January 2006:
I do think that focus is beginning to emerge through, or despite, it all. Unfortunately the two outside sources whose feedback I sought are buried under SIGGRAPH submissions. On the upside, hopefully I'll get some interesting papers to read fairly soon. On the downside, no feedback for a while.
Interregnum: In the midst of that last paragraph, local network conditions melted down completely and after an hour or so, I gave up and left. I've finished out my sentence, but hence the abrupt ending. I *heart* NFS.
13 January 2006:
Now, imagine you have an n * m float array on the CPU named buffer[] that you streamRead() into an n x m stream named s<> (created via stream::create(m, n)). You might expect that buffer[ x + y * m ] is the same as s[x][y]. Nope. It is, however, the same as s[float2(x, y)] and the same as s[y][x]. That's right, s[float2(x, y)] == s[y][x] and not s[x][y]. I can't even really blame brook for that because it's really how cg and hlsl operate. I realize there's all sorts of "legacy context" that can be marshalled to defend this. I'm not interested. It remains confusing as hell and each time I go to use 2D gathers or iterators I have to write a little test app to remind myself.
To make matters worse, when using 2D streams as proxies for long 1D streams, the raytracer code sometimes holds the X width fixed at 1024 and varies Y based on total length and sometimes holds Y fixed at 1024 and varies X. Argh. After some quality time with the whiteboard, it seems pretty clear to me that holding X fixed makes the math simpler (regardless of which you hold fixed, the X width determines the 2D <-> conversion so you want it to be a constant). It's also the one that seems more natural to me. Thus, of course, Y is the dimension held fixed for the one set of data beyond my direct control.
12 January 2006:
Over break I came across a few interesting links. Intel posted an article on SSE raytracing back in November that I didn't spot until recently. It goes through some background and nearly the complete code to do traversal and intersection via compiler intrinsics. There's also the latest edition of Ray Tracing News with a bunch of material of varying degrees of interest (to me personally, of course).
And, I finally took the time to go through and read this Master's thesis on GPU raytracing with grids, kd-trees, and BVH's. I've known about it for a while and discussed possible reasons for his BVH so dramatically outperforming a kd-tree with Tim, but hadn't read it. After reading it, I'm a bit disappointed. While at a high level, he implemented kd-trees (or at least the same modified kd-tree algorithm we used), his implementation is suboptimal in lots of ways. Probably the two most important are that his tree nodes are a float4 (2x the size they should be and on a workload he demonstrates is memory bound) and that his implementation is a mixture of multipassing and pixel-shader 3.0 branching I found hard to follow. It certainly didn't sound like there was any z-culling, which is definitely going to vastly inflate the runtime and the branching / looping support in NV4x and G70 is pretty awful as I've described before and as GPUbench results demonstrate. The BVH implementation though, was quite clever.
16 December 2005:
15 December 2005:
As before, these numbers are just the time to walk the rays through the kd-tree (and intersect any primitives), not the time to shade, generate the eye rays, or anything else.
13 December 2005:
One odd thing-- the various bits of documentation encourage enabling flush to zero and denorms are zero mode as allowing faster math. However, it appears that having those enabled also opens me up to this input assist business.
While I was still trying to decipher this, I hacked up the SSE intersection code (and constructor) so that the triangle data was laid out in a more SSE friendly way and I did the reads and shuffles myself instead of hiding them behind _mm_set1_ps(). _mm_set1_ps() actually does a great job if you're reading a single value. When you're reading 12, though, it's better to compress down to 3 128-byte reads and do the shuffles yourself.
A final bit of bad news-- the input assist "impact" (a random scalar vtune produces to allow you to gauge how bad a problem is) gets a bunch worse when I switch from the cbox to the robots. Sigh.
9 December 2005:
I realized that now that I have per-packet intersection, I could turn mailboxing back on, so I added the code and checked the effects. The stat counters show reductions in intersection calculations, but the performance numbers aren't materially affected. Sad, and a little odd.
So, I augmented the stats (and repaired some counters that fell by the wayside when Tim redid the connection between the builder and the accelerator) out of curiosity. There are a lot of empty leaves in our trees. Most of the scenes look to average roughly two triangles per non-empty leaf, but the robots are way higher. Traversal of all the scenes looks to visit primarily empty leaves, which is also interesting.
8 December 2005:
6 Decemember 2005:
2 December 2005:
This is on my 3.4 GHz Pentium 4 with hyperthreading enabled (but only a single-threaded application). The speedup on the cbox and glassner scenes makes me extra suspicious that the SSE-ification of intersection had such an impact for reasons other than raw compute since even in an ideal case it should have maxed out at making only the intersection portion a little less than 4x faster. It'll be interesting to see what impact smoothing the final edges has (prepacking the triangle intersection data better and propagating SSE packed hits end to end). And of course, there's always more optimal intersection routines like the one Ingo (Wald) describes in his thesis.
Also, given how heavily the SSE tracer uses compiler intrinsics that pretty much dictate the resulting assembly, I'm baffled that the debug SSE tracer is so much slower than the release version. With the C tracer, there's roughly a factor of 3 between them. The SSE tracer has a factor around 5. I guess the argument is that once you've truly pared the algorithm down to its essentials, introducing noise (or just debug-friendly assembly) has a larger relative impact. I was still surprised. For reference, in our Makefiles, debug and release mean:
1 December 2005:
For reference, I also benchmarked each of the routines. With release builds, the SSE generation makes 65536 rays in 1.13 msecs and the C version takes 5.18 msecs. The works out to be about 58 million eye rays per second for SSE and 13 million for C. Those numbers remain roughly accurate at 512x512 and 1024x1024 though there's a small falloff at 1024x1024 that I suspect is caused by memory pressure (created elsewhere in the system) as much as anything. They're also stable across scenes (which is good. I'd worry if the CPU could do identical math on certain values appreciably faster or slower than on others). I should note that I haven't heavily optimized either version, though the nature of reformulating the SSE version meant I manually hoisted some computations and precompute some values. So these certainly aren't the best times possible, just a generic data point.
Wow! With SSE eye ray generation and thus more conveniently aligned and packed rays to the SSE traversal, the SSE packet traversal is finally faster than the straight C single ray traversal. And the robots scene is over a million rays per second. Looking at the code, there's some more I can shave by using the SSE representation to quickly detect invalid packets faster (or I could just eliminate them up front, but I'm too lazy) and I can squeeze out a couple of the branches in the inner loop(!) by assigning the new node index to near or far with conditional moves and guarding the stack push with a branch. Bears some testing.
29 November 2005:
18 November 2005:
However, before diving too deeply in there, I've been working on the single ray intersection code. After staring at it for a while and quizzing my officemate on how dot and cross products intermingle, I pulled out a bunch of redundant computation. While I was in there, it seemed like a good time to pack intersection data in the same order as it's stored in the kd-tree nodes instead of randomly accessing into the array of vertices. All told, it definitely helped, but I didn't keep precise numbers.
After that, I decided to bite the bullet and experiment with mailboxing. The results were somewhat confusing. With perfect mailboxing (one mailbox per primitive that stores the id of the last ray it saw. If a ray ever encounters a primitive it's already seen, it just skips that primitive) and 256x256 scenes I get the following:
That seems like a pretty compelling demonstration that mailboxing is useful. At the same time, the cbox numbers don't make a lot of sense. With mailboxing, despite the fact that the mailboxing accomplishes nothing, it makes raycasting more than 5% faster?! I have no explanation. There's a similarly positive effect on the other scenes, but it makes more sense there. I wonder if the compiler's generating different code that has a weird impact.
And no doubt some more variations I'm condensing down.
17 November 2005:
Also, I cleared up my confusion on why the packet tracer saw such a higher MaxIntersections count (number of leaves visited by the packet that visited the most leaves). First off, I was scaling it by the packet size. Secondly though, I only track it across the whole packet, not across the rays within the packet, so imperfections in coherence can inflate the MaxIntersections count for a packet even if no ray actually is active in that many leaves. Pretty obvious in hindsight.
Precision has reared its ugly head again. Take the example of ray 5102 in a 256x256 cbox scene. With the ray at a time code, this ray traverses: far, far, near, near + push, near + push, pop, hit geometry. The ray is only in the cell where it hits geometry from tMin of 1098.60 to 1098.89. As part of an SSE packet, the same ray again starts off far, far, near, near + push, near + push, pop. However, this time it shows up in the node where it should hit geometry with a tMin of 1098.83 and a tMax of 1098.62. Since tMin is larger than tMax, the SSE tracer culls this ray and concludes it misses all geometry. I'm surprised to see that the SSE traversal has that much trouble relative to standard C floats. I know there are a variety of SSE math styles available at a trade off of speed for precision, but I didn't select any of those. The only saving grace is that with a SIMD+SSE triangle intersector, I'll compute those intersections even for 'inactive' rays (because it'll be effectively free). That would catch this case, but it wouldn't help in general (if precision caused us to stop traversing one node sooner).
At this point, the stats look pretty competitive-- the packet tracer isn't doing that much extra work:
Stats for module kdtreeCPU (cbox 256x256 single ray at a time)
kdtreeCPU:Traversals 730616
kdtreeCPU:TraverseLeaves 178118
kdtreeCPU:Intersections 140214
kdtreeCPU:Push 141189
kdtreeCPU:Pop 112582
kdtreeCPU:MaxIntersections 9
kdtreeCPU:MailboxHits 20
kdtreeCPU:MaxStackDepth 5
kdtreeCPU:TriMissTHit 195
kdtreeCPU:TriMissBary 73994
kdtreeCPU:TriHit 66025
Stats for module kdtreeCPU (cbox 256x256 sse 4 rays at a time)
kdtreeCPU:Traversals 750128
kdtreeCPU:TraverseLeaves 185968
kdtreeCPU:Intersections 140333
kdtreeCPU:Push 151096
kdtreeCPU:Pop 121252
kdtreeCPU:MaxIntersections 11
kdtreeCPU:MailboxHits 19
kdtreeCPU:MaxStackDepth 5
kdtreeCPU:MissGeometry 1
kdtreeCPU:MissBadPacket 1024
kdtreeCPU:HitEmptyStack 3
kdtreeCPU:TriMissTHit 253
kdtreeCPU:TriMissBary 74056
kdtreeCPU:TriHit 66024
The 'MissGeometry' and 'HitEmptyStack' stats are poor ray 5102 and its
packet mates. The BadPacket count is the number of packets whose
direction vectors didn't agree in sign in at least one direction and
were traced ray at a time.The bad news is that the packet tracer isn't dramatically faster than the single ray tracer. In fact, the debug version is consistently slower (at least, for cbox), but the release version is slightly faster (again, for cbox). With the bunny, even the release packet tracer is slightly slower than the release single ray tracer. There is a ray of hope in all of this (pardon the pun). If I remove all the leaf intersection code and just test raw traversal speed, the release sse tracer is 2x the release single tracer for the cbox and a dinky 20% faster for the bunny.
15 November 2005:
if (hits[ii].tHit > tMaxVec[ii]) { allDone = false; }
if (hits[ii].tHit < tMaxVec[ii]) { allDone = false; }
That's right, I would declare a packet not done if any ray's tHit were
less than or greater than tMax. Clearly I meant tMin for the latter
condition. And, as I thought about it some more, I didn't even need
the latter condition. The good news is my performance is no longer
pathological for big scenes (the effect of the bogus check was that no
packet ever finished until it walked off the end of the whole kd-tree.
So, more geometry led to bigger trees led to huge performance gaps.Sadly, even that fix doesn't get me the legendary packet tracing speedup and I still see more intersections than the single ray at a time case. I worked through a simple example on the board and the wrinkle seems to come in determining when a packet is done. Here are two problematic scenarios: ray1 hits a primitive in the current cell. It's now done, but rays2-4 are still going. As long as the packet continues to traverse cells that ray1 would have traversed (if it hadn't hit anything) than my code will consider ray1 'live' and keep intersecting it with primitives, all of which will be rejected as worse hits than its current hit (after all, the current hit is the best possible hit, ray1 should be done).
Problem two: ray1 hits a primitive, but the packet keeps traversing because rays2-4 don't. Later, rays2-4 hit a primitive in a cell ray1 wouldn't have visited. That means, given the current algorithm, that ray1's current tMax is less than tMin which means tHit for hit1 is definitely less than tMax. It's hard to capture the proper tMax against which ray1's tHit should be tested since the algorithm goes out of its way to clobber tMax for inactive rays.
And now xenon has crashed while I was in the middle of mail trying to work out whether one of the stack values is truly redundant. Grr. I guess that means it's time to go home.
11 November 2005:
We're still doing vastly too many intersections (and, to some extent, traversals). I know my masking is very conservative right now, so hopefully tightening it up fix the problem.
10 November 2005:
Wow! That's certainly an interesting effect. Sort of like looking at the Cornell Box through a screen door whose vertical hatching is wider than its horizontal hatching.
Okay, it's now significantly better (there's a big difference between the SSE instructions that only affect the first component and the ones that affect all four). However, I have to fudge tMax by a lot more (10% or so) to avoid the precision problems with the cbox and it does a whole lot more traversals and intersections than the ray-at-a-time version. I strongly suspect I'm mismanaging the masks. I know I need to get the size of stack elements down. And, I'm suspicious there's some other math problem-- possibly just putting an epsilon fudge factor into the intersection routine since I still see glitching on robots and glassner. Still, progress.
8 November 2005:
Ever suspicious, I decided it was time to bulk up the brook writeQuery regression test. So, I augmented it to do the following:
Nothing special, right? Each drawing pass is wrapped in an occlusion query to count how many fragments are actually drawn. I expect the first pass to draw all size * size fragments, the second pass to draw threshold fragments (because of how the data is initialized) and the final pass to draw size * size - threshold fragments.
On ATI hardware, that's almost what happens. For smaller values of size (below about 490), everything works flawlessly. For larger values of size, only the first 240k or so fragments ever appear to be issued. The first occlusion query always reports roughly 240k and numbers reported by the final two passes sum to the 240k number.
On NVIDIA hardware, no such luck. As long as the depth test is enabled, all of the occlusion queries return garbage (around a few thousand fragments regardless of the specified size) for the two copies and zero fragments (or all fragments. It's random from run to run) for the shader with the fragment kills. Disabling the depth test produces correct results for the first two shaders, but since the third relies upon depth culling, it obviously doesn't work as intended (but it works as it should given that the depth test is disabled).
Here's a copy of the test binary for
reference. Try running "./writeQuery
cbox backtrack 512x512 shortfixed = 2679537 r/s cbox backtrack 512x512 float = 2672713 r/ bunny backtrack 512x512 shortfixed = 378592 r/s bunny backtrack 512x512 float = 376533 r/s robots backtrack 512x512 shortfixed = 269271 r/s robots backtrack 512x512 float = 269068 r/s kitchen backtrack 512x512 shortfixed = 289405 r/s kitchen backtrack 512x512 float = 290543 r/sBottom line: shortfixed was an optimization unjustified by the data. Stray aside-- those numbers are all significantly worse than the ones we report in our paper. I suspect I have the driver developers at ATI to thank for that (given how many driver versions I had to test to find the best ones before). Hooray.
4 November 2005:
Two corollary questions though: Why is this builder so much better than the pbrt builder / Are there minor changes that could be ported with a major impact? And, what effect do these kd-trees have on the GPU traversal / what's the right tree building strategy for a GPU targeted traversal?
3 November 2005:
Interesting. One consequence obvious in hindsight (but I had to look at the stat counters to realize it) is that there are a whole lot fewer traversals for the same scenes. For the kitchen numbers below, the default kd-tree makes 95183 traversals and the GPU-friendly one makes 67411. Now, traversal only needs to be 11.2x the speed of intersection in order for that to be a good trade. It's still not a good trade, at least for debug builds, but the default kd-tree is only about 5% slower instead of vastly slower (which is to say I didn't record the number, but it was tens of percentage points).
Stats for module kdtreeCPU
kdtreeCPU:Nodes 185069
kdtreeCPU:Splits 92534
kdtreeCPU:Leaves 92535
kdtreeCPU:EmptyLeaves 25250
kdtreeCPU:Traversals 236591
kdtreeCPU:Restarts 13081
kdtreeCPU:Intersections 31817
These are from the tree generated by the GPU-friendly rules:
Stats for module kdtreeCPU
kdtreeCPU:Nodes 107841
kdtreeCPU:Splits 53920
kdtreeCPU:Leaves 53921
kdtreeCPU:EmptyLeaves 10394
kdtreeCPU:Traversals 142922
kdtreeCPU:Restarts 11244
kdtreeCPU:Intersections 34296
So, the GPU-friendly tree causes a bit under 8% more intersections, but
nearly a 40% reduction in traversals. In order for that to break even,
let alone be a good trade, traversal needs to be nearly 38x as fast as
intersection. I don't think I'm quite there...
The "measure and adjust" phase is blocked behind my acquiring a reasonable profiler, but VTune has eval licenses while we see whether or not we can con Intel into donating some.
1 November 2005:
Well, now the code seems to be correct (modulo restart having some awkward boundary conditions), but still speckled. And still not so fast. Well, the release build gets over 1.5 million rays per second on the cbox, but it's down below 400k rays per second for the kitchen. Definitely time for some more optimizing.
An interesting note-- the cbox throughput halves when I switch to the GPU-friendly kd-tree construction parameters, but the kitchen performance goes up 20%. Clearly I'm still doing a poor job with deeper trees.
28 October 2005:
The CPU kdtree has landed.
Initial version of CPU kdtree support. We use the same builder as the brook
kdtree and then repack the results into our preferred format. I didn't
implement a stack yet, so I use the restart algorithm instead. I'm almost
certain I did something wrong because a number of the images are incorrect
in places, especially if I tweak the various tree creation parameters.
Specific changes:
- Compile LOG() and LOG_ONLY() out of release builds completely.
- Convert f3 from a struct with .[xyz] to an array of 3 floats. I toyed
with making them a union for syntactic convenience and decided the
nuisance of vector.components.x vs. vector.array[0] outweighed any
potential clarity.
- Beef up the timing and stats reporting for the CPU tracer.
- Fix intersectRay() to take a const RayCPU& instead of copy-constructing
a ray (oops).
- Pull the ray-triangle intersector into a header file so all the CPU
accelerators can share it.
- Add F3_INV and F3_FROM_FLOAT3 / FLOAT3_FROM_F3 to facilitate
conversions.
- All the kdtree code (obviously).
- Clean up some bogus status messages.
- Attempt to restore the Cornell Box lighting to a close approximation of
its original form. The coloured lights were cool in a tie-died sort of
way, but made it harder for me to spot problems in the image while
debugging.
Hooray. Now I really need to nail down the incorrections and then
optimize it. Sadly, it's already as fast as the GPU versions as it
stands.
27 October 2005:
25 October 2005:
14 October 2005:
Well, I got distracted and simplified the shading code instead. It was slightly relevant to my larger goal of reducing the amount of stream-state so that I can substitute in CPU-back routines. Only slightly, though. Ah well, time to go not drink repeatedly filtered cheap vodka.
6 October 2005:
Tim ran the simple hacked up pixel-shader 3 kd-tree raytracer and it was in impressive over 1 million rays per second territory. It's completely unoptimized, but a strong endorsement of looping and branching for hardware that has realy granularity. The gpubench test isn't available since the board only supports pixel-shader 3 under D3D, but reputedly (and apparently, judging from results), it needs far less coherence than the 64x64 or 128x128 that the 6800 and 7800's need.
In other news, new employee orientation at nvidia wasn't a great fit for my role as a (very) part-time intern, but the HR people were friendly and helpful, I actually did have a cube and a machine, and we managed one long constructive briefing / conversation on technical issues before I turned into an erev Rosh Hashannah pumpkin.
Addendum: I forgot to mention that the nvidia IT people somehow managed to turn Tim into a total non-person in the process of converting him from summer intern into school year intern. They took away one of his machines, stole the video card from the other, and completely garbled his user credentials so he couldn't access anything and got really weird errors messages. Most impressive.
26 September 2005:
6 June 2005:
Guess that means back to idly pondering the gpubench / shader analyzing paper.
31 May 2005:
27 May 2005:
19 April 2005:
15 April 2005:
We talked to the GROMACS guys yesterday and I looked over their code. It seems to be the worst sort of expedience-first programming and I suspect a lot of that derives from its roots in Ian just hacking both Brook and the .br files to try and get through his thesis. It certainly seems a start contrast to the raytracer in terms of organization and readability (but that may be influenced by the fact that I know the raytracing code so well and chose the organization). In any event, I think it would be ideal to try and educate them a lot more on the constraints and strengths of the hardware (and underlying Brook implementations).
For whatever reason, Pat was interested in our chief grievances for getting good performance from the nvidia hardare, so I drafted my thoughts (this version has been tidied a little and made more precise after some comments from Kayvon).
12 April 2005:
11 April 2005:
Now I really, really, need to study for quals. Instead, I'll read GPU Gems 2 for a while.
7 April 2005:
My bandwidth gloom and doom of last spring has proven somewhat overstated. At least the ATI hardware is roughly 2 clock per float pulled across the bus and the raytracing kernels aren't so far off. I guess the saving grace is that they aren't vectorized so they do so little math. We're actually compute bound on bruteforce, but only by about 1 instruction. Still, I'd anticipated being heartily bandwidth bound. Ironically, of all the kernels, the kd-tree downwards traversal kernel is the only one that's clearly compute bound. So much for fast and cheap traversal. The poor voxelgrid traversal is massively bandwidth bound, but part of that is ATI's committment to throwing performance out the window if you have 3 or 4 render outputs.
Actually, one major repeated pain point in this whole thing has been getting stuck with the ATI hardware. I have to concede that it actually works whereas the NV4x using D3D bluescreen running the kd-tree and just produce inexplicably erroneous ray-triangle intersectiosn with the voxelgrid. However, everything about using it is a struggle. Last weekend I installed every driver from 4.9 through 5.3 looking for one that was stable and sane and each one caused at least one kernel to plummet or shoot up in performance (and it was all different kernels and all different improvements or harm). Daniel and Mike found that the 5.3 drivers cut their performance by more than a factor of 3x relative to 4.10! Today yielded 5.4 drivers and they're somewhere in the middle of the fray too. Don't even ask about GL, either. The Brook regression tests just plain won't run unless you back all the way off to 4.9 because of bugs in pbuffer handling. Oh, and numerical precision is apparently optional. I can ruefully shake my head at 16-bit mantissas and realize the implications, but we found an even more fun item when Tim was trying to determine why the restart tree was broken: sometimes <= just doesn't work. We needed to add an additional case to handle two values being equal because the board conclude that the "or equals" part of <= was just us joking around.
In other gpubench news, apparently some marketing people in the world have nothing better to do than web searches for gpubench results and then tamper around with the URL until they find more.
28 March 2005:
GPUBench results now available and for no good reason the PCIe board appears to have about 2x the readback rate of the AGP board. No good reason meaning it's still only 200 MB/s so it's not like it's bus bound (as a matter of fact, it's about 10x away from being bus bound). So much for PCI express solving the world's readback and download problems.
And, the DX9 version of the raytracer even seems to run correctly. That'll be quite helpful for gathering non-timing data instead of constantly running out to the lab.
17 March 2005:
Looks like I'm not the only one viewing 'branching' with a jaundiced eye.
15 March 2005:
if (tex0[texCoord0] >= t) {
discard; /* kill this fragment */
}
result.color = tex0[texCoord0];
and wrap the whole thing in an occlusion query to determine how many
fragments are below the threshold. It's a simple test exactly
equivalent to my brook writeQuery test. Testing my NV41 shows that
GL occlusion queries shouldn't be as slow as I've been seeing:
(* size usecs per query queries/sec *)
128 26.6539 37518 (* 8058 *)
256 63.2904 15800 (* 32505 *)
512 208.8024 4789 (* 130736 *)
1024 771.0500 1297 (* 524323 *)
2048 3070.4773 326 (* 2096241 *)
Unfortunately, testing the X800 produces all zeroes in the framebuffer
/ pbuffer and always returns a count of the resolution drawn. That's
right, not only does it draw no samples, it claims it drew all of them.
I wonder how I'm supposed to be issuing occlusion queries on ATI
cards.
Apparently, strictly speaking, occlusion queries require the depth test be enabled. Who knew? Not my NV41, which doesn't mind if I leave depth off. The folks at ATI know, though, and reserve the right to report completely bogus results if depth is not present. Better still though, it takes exactly as long to report these incorrect results as to report correct ones. To top it all off, my GL occlusion queries there are an extra 30+ times slower than on NV41. It takes the card around 110 msecs to report incorrect results. The DX numbers are quick and, once I added depth, even correct.
14 March 2005:
Unfortunately the GL fast reduction / query is fairly slow compared to the D3D version (nearly 10x slower). I suspect it's the copy from the framebuffer of the (unneeded) output. Grr. The D3D version benefits immensely because not only are the queries so much faster, readback is so much slower.
Ah. Hacking it up to compile with gpubench instead of glut produced a working test. And, indeed, its barebones throughput numbers are quite impressive (over 1500 MB/sec on my NV41). Unfortunately, actually touching the data (i.e. read the contents of the buffer) halves throughput back down to the same ranges we've been seeing all along.
10 March 2005:
4 March 2005:
The grid is faster and more robust than it's ever been, but sadly bruteforce still has it beat. Poor poor missing earlyz.
3 March 2005:
That was more aggravating, but less justified, than the fact that the code that computed tMax would end up with negative infinity instead of positive infinity for parallel rays. That little trick (which was just a greater-than instead of greater-than-or-equals) caused the code to always traverse the wrong way its first time.
28 February 2005:
One big concern / nuisance in this whole thing is the miasma of hardware and driver issues. Currently only the DX version of Brook supports earlyz and occlusion queries. The latter is easy enough to add to GL, but useful earlyz really requires read-modify-write access to textures which, even with FBOs, we can't currently get on GL. However, the DX version of the raytracer is an instant bluescreen on NV4x with any acceleration structure and just a garbled image with bruteforce. However however, we only have the one X800 and it has a few quirks of its own (most notably precision). So we can either commit to DX, which will leave us with one board between two people (and the 9800s just fail fetching triangles for no good reason) or we can use the NV4x's we have. I sent some more mail off to our friends at nvidia and prepared demo versions of the bluescreen shader and my FBO demo. Hopefully it'll turn out to be some bug (heck, hopefully even our bug so we can fix it) that's easily resolved. A boy can hope, can't he?
24 February 2005:
Allocate texture texID and fill it with input data
for (i = 0; i < count; i++) {
glBindTexture(GL_TEXTURE_RECTANGLE_EXT, texID);
glFramebufferTexture2DEXT(... texID ...);
/*
* Rasterize a quad with a shader that writes:
* result.color = texture0[texCoord0] * 4;
*/
}
I was hoping the test would just work (i.e. after count iterations, the
framebuffer and texture would contain 4^N time the original input). I
was prepared for errors or garbage results. The nvidia driver
developers still managed to catch me by surprise, though. The result
of the above is that after count iterations (or any other number) the
framebuffer contains exactly 4 time the original input and the input
texture is unchanged. Somehow 'render to texture' became 'render to
framebuffer, but skip copying back to texture'. If I modify the same
test to allocate two textured and ping pong back and forth then
everything works as expected. 'Tis a pity.
22 February 2005:
21 February 2005:
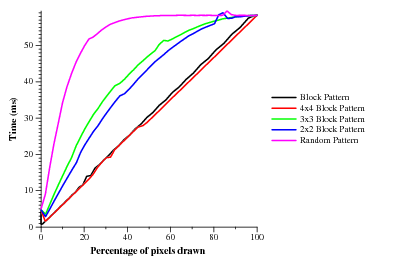
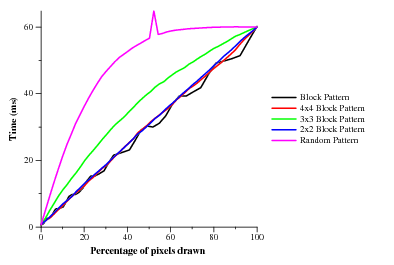
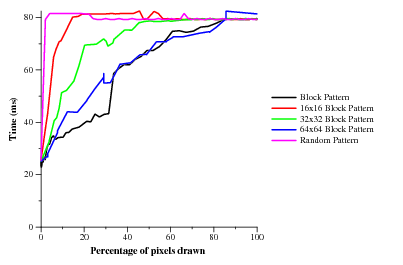
I did some more pushing on the branching code to get an idea of granularity and have some interesting graphs. As I'd already seen, earlyz is just way better than pixel-shader 3.0. Here are the results of from my nv41 and the X800 in the lab. The NV41 seems to have an earlyz tile size of 4x4 (or possibly 2x4 since I only tested squares) while the X800 is 2x2 (or 2x1).
Now meet ps30 (NV41 only. ATI doesn't have any ps30 parts currently)! Not only is it slower in all cases (note the y-intercept when no pixels are being drawn and the value when 100% of the pixels are being drawn), but it requires huge coherence. My card only has 12 pipes, so even requiring all currently executing fragments to branch the same way wouldn't be too onerous. Instead, it looks like most (all?) of the pixels in flight all have to be taking the same branch. It'd be nice to run a test where both sides of the branch (i.e. taken and not-taken) do heavy math, just different heavy math. It's not so bad if that ends up taking the longer of the two sides' execution time. If it takes the sum though, ouch.
18 February 2005:
Unfortunately, playing with it interactively drives home exactly how much faster the 'bruteforce' approach is to the uniform grid for our scenes and the current code. The brute force approach can do even the glassner scene at about 10 fps while the grid is under 1 fps. Part of the delta is that currenly the grid reads back each iteration to tell how many rays are live, but even if I hack it to only run the correct number of iterations without reading back, the grid is still probably 8-10x slower for the cornell box. Moral of the story: (1) we need better (and bigger) scenes and (2) the grid code needs some attention. The big nuisance with the grid is the lack of summary statistics (i.e. it's hard to count how many rays are traversing / intersecting / or shading without running an expensive reduction or reading back). They can probably be faked with occlusion queries, but it's unclear how cheaply. The more urgent need is more efficient traversal and intersection and that probably means earlyz. Just packing some needless float4's into float1's may help a lot too (given the NV40 pathology with non-float1 textures and the texture cache).
And now I really need something to talk about Tuesday. Or at least some structure to collect all the various irons I've got going into coherent unified form.
15 February 2005:
14 February 2005:
GPUBench indicates that, in addition to being more correct, the drivers perform better in some nice ways. Their sequential texture fetch bandwidth about doubled and data dependent random texture fetch went up by 4x! Fill rates for float2-4 buffers also doubled, but are still only half that of an X800. The raw numbers for the card finally beat a 9800XT across the board though...
9 February 2005:
Anyhow, I finally augmented the main script to generate early-z and pixel shader 3.0 (where available) conditional execution results and modified the instruction issue test so that it can test a range of sizes. The NV41 ramps up pretty quickly-- if you run 10 iterations of a 64 MUL kernel then you get nearly peak GFLOPS even at 64x64. Kayvon's suspicious that the ramp up is much slower when texture fetches are involved so he's going to write his own test and then we can make graphs of the ramp both with and without texture fetches.
3 February 2005:
Sadly, while I now have pbuffers, it looks like GL_TEXTURE_RECTANGLE_EXT isn't supported, which is going to be a big nuisance. Time to try the beta drivers and send some more email.
1 February 2005:
kernel void
crashKernel(float4 in1<>, float gat1[], out float4 out1<>, out float4 out2<>)
{
float val;
val = gat1[0];
out1 = in1;
if (val < 0) {
out2 = float4(0, 0, 1, 0);
} else {
out2 = float4(0, 1, 0, 1);
}
}
int main(void) {
float4 input<1>, out1<1>, out2<1>;
float gat<1>;
float4 out1_d[1];
crashKernel(input, gat, out1, out2);
streamWrite(out1, out1_d);
return 0;
}
Hopefully the nice people at nvidia will be able to figure out what's
going wrong and suggest a workaround.
31 January 20005:
"PARAM c[6] = { program.local[0..4],\n"
" { 0, 1 } };\n"
"TEMP R0;\n"
"TEMP H0;\n"
"TEMP RC;\n"
"TEMP HC;\n"
"MOVR R0.y, c[5].x;\n"
"MOVR R0.x, c[3].z;\n"
"TEX R0.x, R0, texture[9], RECT;\n"
"SLTR H0.x, R0, c[5];\n"
"TEX result.color, fragment.texcoord[1], texture[3], RECT;\n"
"MOVRC HC.x, H0;\n"
"MOVRC HC.w, H0.x;\n"
"TEX result.color(EQ.w), fragment.texcoord[2], texture[4], RECT;\n"
"MOVR result.color[1], c[5].xyxy;\n"
"MOVR result.color[1](NE.x), c[5].xxyx;\n"
"END \n"
Another indication that either all results must be written
conditionally or none.
virtual unsigned int getMaximumOutputCount() const { return 1; }
is (rightfully) picky about letting you override it. For example, the
following:
virtual unsigned int getMaximumOutputCount();
does not suffice. Nor, of course, does the C++ compiler complain.
After all, for all it knows, maybe you really did want to define a new,
non-const method that just happens to have the same name as an
inherited, but const, method. Happens every day. Anyhow, adding the
word const to the latter instance unconfused the OpenGL brook runtime
when handling multiple output shaders. Embarassingly, the confused
OpenGL runtime still generated less breakage than allegedly legitimate
D3D and OpenGL display driver. (I didn't say it was embarassing for
the runtime).Now, the meat. I decided I'd spent enough time chasing the dx9 BSOD for now and was going to try to figure out why the fp40 version of the raytracer generated a weirdly broken image. However, when I ran the fp40 version of the BSOD shader, Windows cheerfully informed me:
raytracer.exe has encountered a problem and needs to close. We are sorry for the inconvenience.DevStudio told me moments later that I'd branched to hyperspace. Hours of debugging later, all of our code looks legitimate (modulo calling glDrawBuffersATI() twice back to back for fun) and glBegin(GL_TRIANGLES) causes the offending wild branch. Chalk up another kill for the display driver.
At this point, I resorted to tampering with the generated assembly. Here's what cgc produced (the #if's are my additions):
"PARAM c[6] = { program.local[0..4],\n"
" { 0, 1 } };\n"
"TEMP R0;\n"
"TEMP RC;\n"
"TEMP HC;\n"
"MOVR R0.y, c[5].x;\n"
"MOVR R0.x, c[3].z;\n"
"TEX R0.x, R0, texture[9], RECT;\n"
"SLTRC HC.x, R0, c[5];\n"
#if 1
"TEX result.color, fragment.texcoord[1], texture[3], RECT;\n"
#endif
"MOVR result.color[1], c[5].xyxy;\n"
#if 1
"MOVR result.color[1](NE.x), c[5].xxyx;\n"
#endif
"END \n"
Intriguingly, changing either '#if 1' to an '#if 0' produces a shader
that runs without hyperspacing the GL driver. Apparently a mixing
predicated output writes with non-predicated ones is evil. Someone
should mention this fact to either cgc or the driver authors. Or
both.Remaining unanswered questions: Is this the reason the fp40 and arb versions of the raytracer look incorrect? I.e. can this sort of problem lead to incorrect results instead of the more heavy handed outright crash? Why do we crash? Is it just a driver bug or are we violating a hardware constraint? In the latter case, the failure mode mystifies me. Oh well, I can't think about that right now. If I do, I'll go crazy. I'll think about that tomorow. After all... tomorrow is another day.
29 January 2005:
kernel void
krnValidateIntersection(Ray ray<>, Hit candidateHit<>,
float3 grid_min, float3 grid_vsize, float3 grid_dim,
Hit prevHit<>, TraversalDataDyn travDataDyn<>,
RayState oldRayState<>, GridTrilist triList[],
out Hit hit<>, out RayState rayState<>)
{
#if 1
/*
* This kernel will crash with the dx9 runtime
*/
float triNum;
triNum = triList[0];
hit = candidateHit;
if (triNum < 0) {
SET_SHADING(rayState);
} else {
SET_INTERSECTING(rayState, 1);
}
#else
/*
* This kernel will not crash with the dx9 runtime
*/
float triNum;
triNum = triList[0];
if (triNum < 0) {
hit = candidateHit;
SET_SHADING(rayState);
} else {
hit = prevHit;
SET_INTERSECTING(rayState, 1);
}
#endif
}
The calling C++ code is literally just a kernel invocation and a
streamWrite() of rayState. I ifdef'ed out the rest and it still
bluescreens. Unfortunately, my attempts to replicate the crash by
hacking up the multiple_outputs Brook regression test have all failed
thus far. Ah well, out of time.
28 January 2005:
STOP: 0x0000008E (0xC0000005, 0xBF2936BD, 0xB466AE58, 0x0000000) nv4_disp.dll - Adress BF2936BD base at BF012000, DateStamp 4182eb4eProbable English translation: "Device drivers actually have to check that their pointers are valid before dereferencing them?! I knew I forgot something." Making my buffer 100x as large doesn't help the situation either. Sigh. Guess that's enough for today. Good thing I keep letting Windows upload the crash dumps to its mothership. I'm sure some grateful support person at nvidia will welcome my data.
Since I'm a sucker, once everything was up and working, I decided it was finally time to take the ol' Realizm 100 for a spin. I pulled out the NV leafblower and replaced it with the inexplicably even larger 3dlabs card and went to work. (Aside, 3dlabs apparently has a "device driver" named Heidi:
The 3Dlabs Heidi Device Driver is an interface for the Wildcat Realizm driver and AutoCAD applications. The Heidi driver provides improved performance and compatibility with AutoCAD applications and the hardware acceleration of the Wildcat Realizm video card through the use of OpenGL.this is not their display driver, just some extra driver in case you thrive on confusion when downloading software). Anyhow, it quickly became clear that GPUBench wasn't going to play well with others. Despite the fact that the contact for all of the OpenGL extensions involving floating point buffers and textures seems to have an @3dlabs email address, issuing actual ARB wgl and gl calls makes the driver angry.
So I tried the readback test, which only really requires that glReadPixels() works. Death. Even in fixed point mode. Then I decided to run each format one by one and discovered two things: GL_ABGR_EXT no supporto, but RGBA and BGRA readback is pretty darn fast (roughly 1 GB/s). Just when you're ready to believe that fast readback on AGP is a myth, it's 3dlabs to the rescue!
27 January 2005:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}