Click slide for next, or goto previous, first, last slides or back to thumbnail layout.
Click slide for next, or goto previous, or back to thumbnail layout.
View-based Rendering: Slide 6 of 17.
Click slide for next, or goto previous, first, last slides or back to thumbnail layout.
Click slide for next, or goto previous, or back to thumbnail layout.
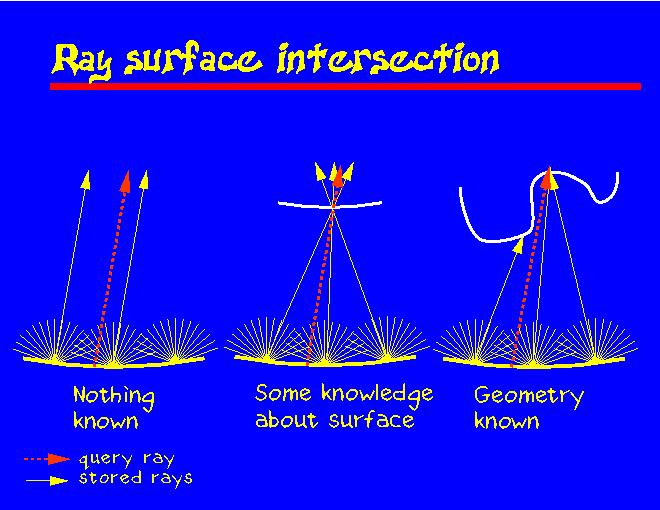
Let's assume that we have resampled the input rays onto the lumigraph surface as shown in the slide: at regular intervals we have pencils of rays.
There is a lot of redundancy since many rays see the same surface locations. But in pure image-based rendering we typically don't know where the surface is, so we have to look for rays that are as close and as parallel to the query ray as possible. The expected error is proportional to how far the pencils are from each other.
With a bit more information about the geometry we can estimate where the query ray intersects the object, and then choose rays that point there. Using the same number of input rays we can expect a lower error, or for a given error tolerance we need much fewer rays.
And of course, the more we know about the surface geometry, the more accurately we can choose the rays.
The main idea here is that there is a continuum between model-based and image-based rendering, and the tradeoff is how many input images are needed vs. how much you need to know about the surface geometry.