
James Hegarty
Computer Science Ph.D.
jhegarty at stanford dot edu
Gates 381
I am a computer science Ph.D. student at Stanford advised by Pat Hanrahan, graduating in 2016. My research interests involve creating hardware/software systems that expand the boundary of what can be computed efficiently. I am particulalry interested in creating hardware that allows key applications to support larger problem sizes, or be computed with lower latency and power. The last few years I have worked on developing Darkroom and Rigel, compilers that take a domain-specific image processing language and lower it to hardware descriptions for efficient FPGA implementations and custom hardware.
Image Processing Hardware
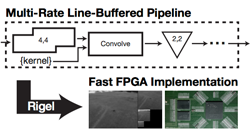 Rigel: Flexible Multi-Rate Image Processing Hardware
James Hegarty, Ross Daly, Zachary DeVito, Jonathan Ragan-Kelley, Mark Horowitz, Pat Hanrahan
Rigel: Flexible Multi-Rate Image Processing Hardware
James Hegarty, Ross Daly, Zachary DeVito, Jonathan Ragan-Kelley, Mark Horowitz, Pat Hanrahan
SIGGRAPH 2016
Project Website
Image processing algorithms implemented using custom hardware or FPGAs of can be orders-of-magnitude more energy efficient and performant than software. In this paper, we present Rigel, which takes pipelines specified in our new multi-rate architecture and lowers them to FPGA implementations. Our flexible multi-rate architecture builds on our prior Darkroom system to support pyramid image processing, sparse computations, and space-time implementation tradeoffs. We demonstrate depth from stereo, Lucas-Kanade, the SIFT descriptor, and a Gaussian pyramid running on two FPGA boards. Our system can synthesize hardware for FPGAs with up to 436 Megapixels/second throughput, and up to 297X faster runtime than a tablet-class ARM CPU.
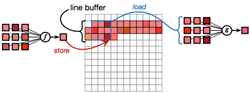 Darkroom: Compiling High-Level Image Processing Code into Hardware Pipelines
James Hegarty, John Brunhaver, Zachary DeVito, Jonathan Ragan-Kelley, Noy Cohen, Steven Bell, Artem Vasilyev, Mark Horowitz, Pat Hanrahan
Darkroom: Compiling High-Level Image Processing Code into Hardware Pipelines
James Hegarty, John Brunhaver, Zachary DeVito, Jonathan Ragan-Kelley, Noy Cohen, Steven Bell, Artem Vasilyev, Mark Horowitz, Pat Hanrahan
SIGGRAPH 2014
Project Website
Specialized image signal processors (ISPs) exploit the structure of image processing pipelines to minimize memory bandwidth using the architectural pattern of line-buffering, where all intermediate data between each stage is stored in small on-chip buffers. This provides high energy efficiency, allowing long pipelines with tera-op/sec. image processing in battery-powered devices, but traditionally requires painstaking manual design in hardware. Based on this pattern, we present Darkroom, a language and compiler for image processing. The semantics of the Darkroom language allow it to compile programs directly into line-buffered pipelines, with all intermediate values in local line-buffer storage, eliminating unnecessary communication with off-chip DRAM. We formulate the problem of optimally scheduling line-buffered pipelines to minimize buffering as an integer linear program. Finally, given an optimally scheduled pipeline, Darkroom synthesizes hardware descriptions for ASIC or FPGA, or fast CPU code. We evaluate Darkroom implementations of a range of applications, including a camera pipeline, low-level feature detection algorithms, and deblurring. For many applications, we demonstrate gigapixel/sec. performance in under 0.5mm2 of ASIC silicon at 250 mW (simulated on a 45nm foundry process), real-time 1080p/60 video processing using a fraction of the resources of a modern FPGA, and tens of megapixels/sec. of throughput on a quad-core x86 processor.
Real-Time Micropolygon Rendering
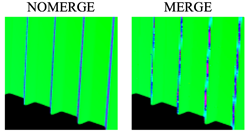 An Implementation of Quad-Fragment Merging for Micropolygon Rendering
James Hegarty
An Implementation of Quad-Fragment Merging for Micropolygon Rendering
James Hegarty
Undergraduate Thesis, 2010
Current graphics cards (GPUs) shade small polygons inefficiently. When surfaces are represented using micropolygons of less than a pixel in size, many shading computations performed by a GPU are redundant. Since shading is typically the most expensive operation in a graphics pipeline, this leads to poor rendering performance. This thesis presents a prototype implementation of quad-fragment merging, which reduces redundant shading work by buffering and selectively merging rasterized fragments prior to shading. The prototype quad-fragment merger is described in detail, and evidence is presented that it is amenable to implementation in fixed-function hardware. Performance results indicate that our implementation decreases shader executions by a factor of eight when rendering micropolygons, and effectively makes use of a number of optimizations to yield high performance. Finally, an early prototype of a corollary technique that shades scenes with motion blur is described, and preliminary results are presented.
 Reducing Shading on GPUs using Quad-Fragment Merging
Kayvon Fatahalian, Solomon Boulos, James Hegarty, Kurt Akeley, William R. Mark, Henry Moreton and Pat Hanrahan
Reducing Shading on GPUs using Quad-Fragment Merging
Kayvon Fatahalian, Solomon Boulos, James Hegarty, Kurt Akeley, William R. Mark, Henry Moreton and Pat Hanrahan
In Proceedings of SIGGRAPH 2010
Current GPUs perform a significant amount of redundant shading when surfaces are tessellated into small triangles. We address this inefficiency by augmenting the GPU pipeline to gather and merge rasterized fragments from adjacent triangles in a mesh. This approach has minimal impact on output image quality, is amenable to implementation in fixed-function hardware, and, when rendering pixel-sized triangles, requires only a small amount of buffering to reduce overall pipeline shading work by a factor of eight. We find that a fragment-shading pipeline with this optimization is competitive with the REYES pipeline approach of shading at micropolygon vertices and, in cases of complex occlusion, can perform up to two times less shading work.
Other Publications
Terra: A Multi-Stage Language for High-Performance Computing
Zachary DeVito, James Hegarty, Alex Aiken, Pat Hanrahan, and Jan Vitek
PLDI '13
Stylizing Animation By Example
Pierre Benard, Forrester Cole, Michael Kass, Igor Mordatch, James Hegarty, Martin Sebastian Senn, Kurt Fleischer, Davide Pesare, Katherine Breeden
SIGGRAPH 2013