Towards a Human-Centered Interaction Architecture
Terry Winograd, Stanford University,
Version of April, 1999
ABSTRACT
This paper proposes a high-level architecture for organizing multi-person
multi-modal interactions in an integrated space that combines multiple
computer systems. The architecture provides mechanisms for coping with
three fundamental properties of human interaction: object-based perception,
individual-dependent interpretation, and action-perception coupling.
1. INTRODUCTION
Computing environments of the late twentieth century have been dominated
by a standard desktop/laptop configuration. A single user sits in front
of a screen with a keyboard and pointing device, interacting with a collection
of applications. As many researchers have pointed out [Buxton 1997, Norman
1998, Streitz 1998b, Weiser 1991], computing today is moving away from
this model in a number of areas:
-
Information appliances, such as PDAs, computers integrated with cell phones
and small specialized information devices of diverse kinds
-
Information environments, which occupy room-sized or building-sized spaces,
making use of large display areas, sound, environmental control, etc.
-
Immersive environments, both head mounted and shared (such as CAVES)
-
Multi-user work environments, with large shared displays and multiple devices
operating in an integrated information environment
-
Deviceless interaction, in which people's normal movements, gestures, vocalizations,
and even physiological parameters are observed and interpreted by the computer
system
Each of these extensions to today's standard computer interaction modes
raises its own technical difficulties and specialized areas of research.
Taking a broader view, it is appropriate to question some fundamental assumptions
about the structure of interactive systems and and integrated environments.
The conventional model of interaction architecture and device communication
that has served as well up until now will have to evolve towards a "human-centered"
architecture. Rather than conceiving of systems as a network of processors
and devices, we will build them around an architecture of user-centered
models, which cut across conventional device boundaries.
This paper presents a conceptual framework for the development of such
an architecture, and discusses some research issues that must be addressed
in implementation. The first section provides a motivating scenario, showing
why interaction spaces require a different kind of interaction architecture
from traditional systems. Subsequent sections present a sequence of increasingly
comprehensive architecture models, moving towards a human-centered architecture:
-
Basic device/program interaction
-
Indirection through drivers and process managers
-
Interpretation by multiple observers
-
Context-specific observer interpretation
-
Generalized action-perception coupling
The final sections discuss some research issues that are being addressed
in applying this architecture to an actual implementation.
1.1 Scenario
Our research group in Graphics and HCI at Stanford University is building
an "interactive workspace", integrating a number of computer displays and
devices in a single room. These devices include large high-resolution displays
(wall mounted and tabletop), personal devices (PDAs, tablet computers,
laser pointers, etc.), and environmental sensors (cameras, microphones,
floor pressure sensors, etc.). The space will support joint work by multiple
users, who can move from device to device and adopt interaction modalities
appropriate to the task and materials. Applications will integrate activities
that involve more than one physical device (e.g., the large display, pointers,
voice, and one or more hand-held devices). A number of similar interaction
environments are being developed, which allow people to interact with the
computer and with each other in the context of large visual displays, (e.g.,
Alive[Maes 1993], HoloWall [Matsushita 1997], VizSpace [Lucente 1998],
Liveboard [Pederson 1993, Moran 1997], DynaWall [Streitz 1998a] , MASH
Collaboration Laboratory [McCanne 1997].) Each has specialized devices
and processes, exploring particular models and styles of interaction.
For the purposes of illustration in this paper, we will consider a small
subset of the desired capabilities, in a scenario of people in an interactive
workspace, developing a complex web site. A large shared wall-mounted display
contains items such as graphs representing the structure of the site, detailed
work plans and schedules, pieces of text, and images. There may be a variety
of other devices and modalities, but we will focus on a small interaction
for purposes of discussion.
-
Jane places her two index fingers on one of the images and slides them
apart and together. As she does, the image expands and shrinks accordingly.
She stops when it is the right size.
-
She touches the screen with her index finger, and gestures a circle around
a few of the images. The images change appearance to indicate selection.
-
She says aloud "Hold for product page."
-
The scaled selected images, are now available for later retrieval under
the category "product page."
This scenario is clearly feasible today and we can expect the hardware
to soon reach a price where the required devices will be commonplace. Each
piece of the functionality has been demonstrated: the recognition of freehand
gestures [Maes 1993]; gesture-based interaction with whiteboard contents
[Moran 1997]; dynamic zooming of images [Bederson 1998], and voice-driven
commands [Bolt 1980]. However, each of the existing systems that provides
some of these capabilities is a research system, in which integration is
limited and a large amount of specialized coding was required to achieve
the desired results.
Consider in contrast an analogous scenario in which the display is on
a standard GUI workstation:
-
Jane clicks the mouse over one of the images. The image displays a set
of associated handles. She drags one of the handles until it reflects a
new desired size and lets up. The image is resized.
-
Jane drags her mouse along the diagonal of a rectangle that encloses several
images, holding down the left button. When she lets up on the button, the
images within the rectangular area change appearance to indicate selection.
-
She invokes the "Hold" menu, which an item for each of the current categories,
and selects "product page."
-
The selected images, in the specified size, are now available for later
retrieval under the category "product page."
This second scenario could be programmed fairly easily by anyone skilled
in the use of any of a variety of interface building tools (e.g., Visual
Basic, TCL/TK, Java tool kits). It is not far beyond what HyperCard made
available more than a decade ago to a wide population of programmers from
elementary school age up. All of the interaction elements (selection, positioning,
command invocation) are available in the basic operating system, or in
the form of widgets, tool kits, and standard libraries.
So why can't we program the first scenario this easily? One answer might
simply be that it takes time for technologies to reach maturity. Because
there are not yet many integrated interaction spaces, there have not yet
been sufficient resources to develop the corresponding mechanisms for new
kinds of interaction. This is, of course, true. But there is a deeper problem
as well. The needed mechanisms are not just new features and widgets, but
require a shift in the way we think about input-output interactions with
a computer: a shift to a human-centered interaction architecture.
2. ARCHITECTURE MODELS
Three obvious elements are needed for human-computer interaction: a person,
a computer, and one or more physical devices that operate in the person's
physical space and exchange signals with the computer. In the early days
of computing, the structure was simple, as shown in Figure 1.
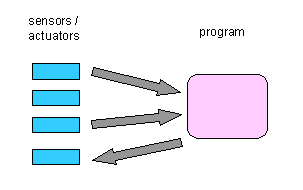
Figure 1: Elementary input/output architecture
A programmer who built an interactive application needed to know about
the specific devices (we will refer to sensors and actuators jointly as
"devices") and the details of their data structures and signals, in order
to write code that interpreted them appropriately. The code could be carefully
tailored to the specific devices, to seek maximal efficiency and/or take
advantage of their special characteristics.
This arrangement worked, but had some obvious shortcomings:
-
Each new program had to have code to deal with the specifics of the devices.
-
Each new device (or modification to an existing device) could require substantial
reprogramming of pre-existing applications.
-
If a computer supported multiple processes, then conflicts could arise
when two processes communicated with the same device.
2.1 Decoupling Devices from Programs
Over the first decades of computing, a more complex architecture emerged
to deal with these problems, using indirection to decouple programs from
device interaction details, as illustrated in Figure 2.
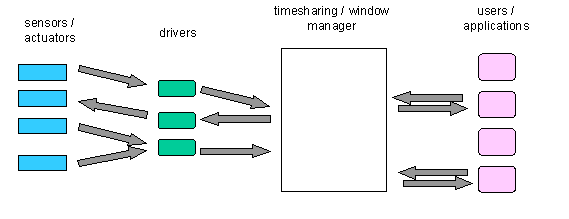
Figure 2: Current input/output architecture
This architecture, which is familiar today, provides two fundamental
levels of indirection between devices and programs. First, the operating
system provides for device drivers, which are coded to deal with the specifics
of the signals to and from the device, and which provide a higher level
interface to programmers. Drivers can unify abstractions for different
devices (for example, different physical pointing devices can provide the
same form of two-dimensional coordinate information), or can provide multiple
abstraction levels for a single physical device (e.g., interpreted handwriting
and digital ink, for a pen device).
An operating system can also provide higher level drivers, which further
interpret events. For example, the basic motions of a pointing device can
be accessed by programs in terms of an event queue whose events are expressed
as high level window and menu operations. Application programs can use
libraries with APIs that provide higher level events and descriptions,
while accessing lower level drivers provided by the operating system.
The second level of indirection is in the linking of devices to programs.
The operating system provides a time-sharing manager and/or window manager
(details have evolved over time), which allocates connections dynamically.
For example, the same keyboard may be interpreted as sending keystrokes
to different programs at different moments depending on window focus. It
is possible for this function to be distributed among multiple processes
and processors, but for the purposes of this discussion we will simply
represent it as a single "Manager" component.
These mechanisms are all at play in making it easy to write a program
that implements the workstation GUI scenario presented above. Selection,
object sizing, menus, the tracking of position as a mouse moves, displaying
a cursor at the location, etc. are all handled by the drivers, libraries,
and toolkits, so the programmer can deal with the events at a level closer
to the user-oriented description.
2.2 Decoupling Devices from Phenomena
The problem in trying to support the programming of our interactive workspace
scenario is not just one of writing more drivers and APIs. There are some
fundamental conceptual shifts.
The first problematic question is "What are the devices?" In the GUI
example there was a mouse and a graphical display. In the interaction space
example, the most obvious candidate devices are "the display, Jane's fingers,
and Jane's voice". But the latter of these are not devices in the sense
of Figures 1 and 2. Although the user (and the application programmer)
may think of them as devices, they are not attached to the computer through
direct signals. Their activity is interpreted through devices such as cameras,
trackers, and microphones. The programmer needs to deal with fingers and
words at an appropriate level of abstraction, just as the GUI programmer
deals with selection and menus. But this cannot be done by simply providing
higher level programming interfaces to the "real" devices such as camera
and microphone.
The tracking of a user's finger may involve the integration of inputs
from multiple visual and proximity-detection devices, along with modeling
of the physical dynamics of the body. This integration is not associated
with specific devices, nor is it associated with an individual program
or application. An integrated "person watcher" would provide information
for any number of different programs, just as the windowing system provides
keyboard and pointing information for multiple programs.
Even for simpler objects, we are beginning to see a separation between
the devices as viewed by a user and those designed into the computer system.
For example, "tangible user interfaces" [Fitzmaurice 1995, Ishii 1997,
Ullmer 1998] incorporate passive or semi-passive physical objects into
computer systems as though they were virtual devices. Programs track these
objects and model their behavior, and then provide a higher level interface
to them.
The architecture of Figure 3 adds an explicit layer of "observers":
processes that interact with devices and with other observers, to produce
integrated higher level accounts of entities and happenings that are relevant
to the interaction structure.
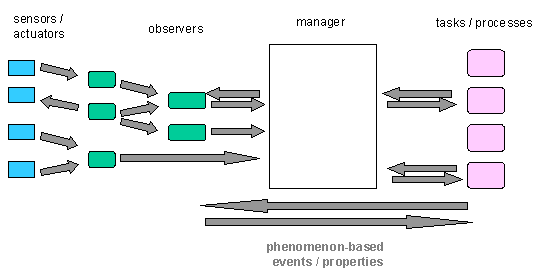
Figure 3: Architecture with a network of observers
The layer of observers has replaced, rather than being added to, the
previous layer of drivers. Device drivers and single-device-based APIs
in current systems can be thought of as simple observers, efficient for
phenomena that are close to the device structure. In general, some observers
will have a close relationship to the devices they interact with (e.g.,
a pointing device will be associated with an observer that reports its
position and tracking devices). A single device may be used by many different
observers (e.g., a camera or microphone that is being used to monitor people
and their voices, track objects, detect environmental sounds and lighting,
etc.). Some observers may maintain elaborate models (for example the detailed
position and motion of a person's body parts).
Each observer provides an interface in terms of a specific set of object,
properties, and events. These can range from low level (" the laser pointer
is at position 223, 4446") to high level interpretations ("Jane made an
'UNDO' gesture on the screen"). Some observers will be "translators" or
"integrators," which do not deal directly with any perceptual or motor
devices, but which take descriptions in terms of one set of phenomena and
produce others (e.g., a gesture recognition observer taking hand position
information from a physical body motion observer, which in turn may take
information from a visual blob observer based on camera input).
The observer processes may operate at different places in the computation
structure, some on separate machines (e.g., a specialized vision or person-tracking
processor), some within the operating system, and some installed as specialized
libraries in the code of individual applications processes. Experimental
operating systems such as Synthesis [Massalin 1989] and Exokernel [Engler
1995] demonstrate the potential for providing flexibility in where processing
occurs, in order to achieve efficiency as needed while maintaining a uniform
conceptual structure.
To summarize this step of expanding the architecture, it separates three
distinct conceptual elements that are often conflated or put into simple
one-to-one correspondence:
-
Devices: (sensors and actuators) and the signals they accept and
produce
-
Phenomena: a space of things and happenings that are relevant to
a program
-
Observers, which produce a particular interpretation of the phenomena
using information from devices.
3. CONTEXT-BASED INTERPRETATION
The examples in the scenario and in the previous section suggest a problem
of interpretation. An application needs to interpret a certain hand motion
as a gesture or a sequence of sounds as a voice. The purpose of providing
a level of indirection through observers is to be able to add general capabilities
such as word and gesture recognition to the overall system (not just to
one application).. But the interpretation of a sequence of motions or sounds
will differ depending on what the application (and the user) is doing,
how the particular person moves and talks, etc. A circular wave of the
hand may be a selection gesture in one activity, and a circle-drawing gesture
(or a meaningless motion) in another. The way that Jane moves her hand
in pointing may be consistent over time, but different from Jim's.
Many programs apply context models to interpretation. In speech systems,
for example, speaker-based models are tuned to the characteristics of a
particular speaker. In addition, task-based vocabularies and grammars set
dynamically by applications can provide a context in which the interpretation
of utterances is shaped by expectations of what would be likely to be said.
In separating the observer from the specific application, we do not
want to create a context-blind interpretation. We need to provide for this
interaction, as illustrated in Figure 4.

Figure 4: Providing interpretive context to observers
Each of the small hexagons represents a context model. Some models are
based in applications (e.g., task-specific vocabularies and grammars).
Some belong to a person in general (e.g., speech or handwriting characteristics)
and can be stored and managed globally. For simplicity in this discussion,
person-based models are shown as part of the manager. In practice, there
will be facilities for maintaining and sharing personal information across
applications and systems. We can imagine each person having an extended
kind of "home page" which provides these models along with other information
about preferences, resources (e.g., personal bookmark collections), etc.
As applications programs run, they provide models to the observers,
and potentially receive updated models from them. This is distinct from
the flow of information about things and happenings, whose interpretation
is based on the current state of the context models. The amounts of data
and required bandwidth will typically be much smaller for events than for
models, and the updating of context models will be correspondingly less
frequent. A speech model for a speaker is downloaded once (possibly even
pre-fetched) for a session, and may be large. The communication while speech
is being interpreted involves a small amount of data specifying words (or
perhaps small word-choice sets with associated probabilities).
4. ACTION AND PERCEPTION
Anyone with experience in writing interactive systems is likely to wonder
whether it is practical to make general use of the levels of indirection
and interpretation that have been described so far. There are two primary
effects of adding a level of indirection to any computing system:
-
Consistent levels of indirection make possible a cleaner separation of
concerns, which makes systems easier to write, modify, integrate, understand,
etc.
-
Consistent indirection requires additional processing across the entire
program, hampering performance.
Whether the structural benefit is worth the efficiency cost is determined
by the specifics of the situation. The world is full of examples of successful
indirection (how many programs today deal with the arrangement of sectors
and tracks on a disk?) and examples of failed indirection in systems where
the gain in generality simply wasn't worth the performance penalty (as
has been the case with many generalized GUI builders).
Many aspects of human-computer interaction have been subject to ever
higher levels of abstraction and indirection, with satisfactory performance
results. Consider, for example, the level at which a programmer specifies
what is to be displayed on a screen. We have progressed from individual
vectors to shaded, textured, 3-dimensional objects with controlled lighting
and viewpoint. Processing power has expanded to make this possible.
The cases where performance has continued to be a deep problem are those
with a tight coupling between action and perception. As a prime example,
consider virtual reality using a head-mounted display. In order to maintain
the perception of immersion in a 3-dimensional world, the visual rendering
needs to be updated to reflect changes in head position with no perceptible
lag. As a more mundane example, we require tight action-perception coupling
in simple cursor positioning with a mouse. If the motion of the cursor
lags too far behind the movement of the hand, effectiveness is greatly
decreased. To operate at action-perception coupling speeds (i.e., a latency
in the milliseconds), system architectures need to pay special attention
to coupling.
Taking a broader view, this coupling is a fundamental phenomenon of
human perception. A person does not have independent sets of input devices
and output devices, but is a tightly coupled system in which the stimulation
of the perceptual sensors is continually changing due to motor action.
In some cases (e.g., running your finger along an object to feel its shape),
the static sensory inputs are almost meaningless, and it is the coupling
that provides information. This coupling has been a central focus of ecological
psychology [Gibson 1979] and perceptual control theory [Powers
1973], with its slogan "Behavior is the control of perception."
Many systems today (from head-mounted VR to the cursor tracker in every
GUI OS) achieve satisfactory action-perception coupling by wiring it in
specially rather than using the more general interaction mechanisms provided
for less time-sensitive processes. This makes it difficult to extend these
programs, as discovered, for example, by anyone who has tried to extend
a standard GUI system to handle multiple users each with a cursor [Myers
1998]. Some such problems are solved in distributed windowing systems (such
as X-Windows) by providing specific coupling mechanisms in the server for
operations such as dragging. On the other hand, if the programmer wanted
to do live rotation instead of translation of an object, this would not
work, since the server does not provide sufficient tools for a rotation
coupling. Specialized platforms for applications such as live-action games
and music-playing provide for coupling within their specialized domains.
A somewhat more general approach was taken in the Cognitive Coprocessor
[Robertson 1989], which had a manager dedicated to maintaining interaction
coupling between a task queue and a display queue. By generalizing the
idea of having the manager maintain couplings specially, we can provide
a modular facility, as illustrated in figure 5.
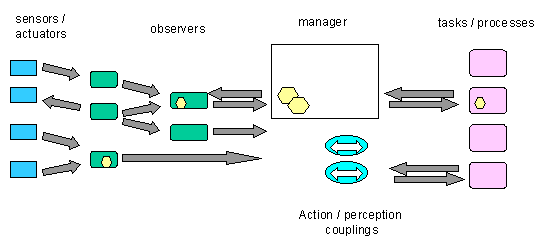
Figure 5: Action-perception coupling
In addition to the basic manager in this architecture, there is a collection
of action-perception couplings, each of which specifies one or more
observers for input, one or more for output, a computation for determining
output changes on the basis of input changes, and timing requirements.
To be effective, the following conditions must be met:
-
The input observers can provide observations at a guaranteed rate that
meets the timing conditions (e.g., the sampling rate of a positioning device)
-
The output observers can guarantee an update rate that meets the timing
conditions (e.g., guaranteed frame rate for visual rendering)
-
The data that needs to be transmitted to and from the manager is small
enough to be transmitted in sufficiently short time (e.g., sending a new
set of coordinates, versus sending an entire image for each change)
-
The computation done by the manager for each iteration of the action-perception
loop can be done within the timing conditions. In general this will not
allow for a callback to the process that created the coupling.
Not all desired action-perception couplings will be able to meet these
conditions. Time characteristics are dependent on the level of control
that is available. For example, in current graphical interface systems,
dragging of objects with the mouse can be done in a coupled way (rather
than dragging an outline), since image translation can be achieved with
sufficient update rates. On the other hand, real time image zooming is
not generally possible, since image scaling is not integrated in a sufficiently
fast way. Systems such as Pad++ [Bederson 1994, 1998] use special purpose
programming to achieve live zooming.
In our plans for the large display in the interaction space, there is
a level of indirection between two-dimensional images and their rendering
on the screen. By using a general OpenGL display model with texture mapping,
the scaling of an image can be specified with a parameter, and the graphics
system does the scaling as part of the display generation on every frame.
Therefore, an input-coupled zooming operation can be implemented as a simple
loop in which the input parameter (e.g., finger position) is used to calculate
a scale parameter, which is then passed to the rendering system. The code
that maintains the coupling need not be either in the applications processes
nor in the central manager, although both are possible. The techniques
of "downloading" critical loops, as developed in the Cognitive Coprocessor
[Robertson 1989] and Exokernel [Engler 1995] illustrate the feasibility
of such techniques.
Current systems with tight action-perception coupling (e.g., head-mounted
display VR) are optimized to maintain one such loop. A more general system
will have to support multiple simultaneous loops. For example one user
may be zooming an image object while another user is dragging a text page
across the screen. The phrase "within the timing conditions" in the criteria
above will be sensitive to the number of simultaneous couplings being handled.
Any particular computational configuration will be limited in the number
of couplings that can be simultaneously maintained. One advantage of separating
the coupling process into the manager is that they can then be allocated
to multiple processors, as long as there is sufficiently fast interprocessor
communication.
5. RESEARCH ISSUES
The human-centered interaction architecture being proposed here is based
on three key elements that extend current general interaction architectures:
-
Networks of observers that integrate information to and from the physical
devices in terms of things and happenings relevant to the world of the
user
-
Interpretive contexts that guide interpretation by the observers, provided
for applications, tasks, and individuals
-
Separately maintained action-perception couplings, to provide guaranteed
latency
None of these are new mechanisms - every system today can be viewed as
implementing one or more of them in some of its operation. The thrust of
the proposal is a shift of perspective to bring these elements to the front,
and to support them in a general uniform way, rather than as special purpose
code.
In order to successfully implement a human-centered architecture, a
number of problems need to be addressed..
Incorporating multiple processors without undue complication
of the manager
The architecture shown in Figure 5 is intentionally noncommittal about
which elements are run on what processor. An observer, for example, may
be a piece of code within the operating system or within one application,
or could be a separate specialized processor communicating through network
protocols (as will likely be the case for observers based on rich input
devices such as cameras and microphones). Device connections will be partitioned
onto processors based on operating system, bandwidth, and other hardware
considerations. Action-perception coupling also depends on high processing
responsiveness. An action-perception coupling might be parceled out to
a processor of its own, if resources are available, or might be one of
several that a scheduler manages in a single processor. The design of protocols
for interacting among multiple conceptual components that have different
communication characteristics is a challenge.
Variable quality guaranteed response rate
One of the criteria for implementing an action-perception coupling is that
the observers can provide guaranteed timing for their activities. The conservative
way to achieve this is to program for the worst case, limiting capabilities
to those that can always be achieved. A more flexible strategy is to have
varying levels of capacity that can be achieved at different speeds. This
has been explored in the area of visual rendering, where a lower quality
rendering may be perfectly adequate for something that is in motion, to
be replaced by a higher quality one when it is static [Bederson 1998].
It is possible to design variable-quality actions, both for input and output,
which make it possible to maintain guarantees of responsiveness by trading
off other resource/quality dimensions. In many cases, the properties of
human perception will aid the programmer, since rapid change will reduce
sensory acuity. In other cases this may not be true, (such as a haptic
system using force feedback in conjunction with fingertip motion over a
virtual object). Both technical and psychophysical questions need to be
explored to make the strategy effective.
Multi-person, multi-device, interaction modes
One of the key motivations for the generalizations in this architecture
is the desire to support integrated applications with multiple users and
multiple devices in an interaction structure that is many-to-many (one
person may use several devices, several people may share one). There has
been a good deal of work on shared-workspace applications, primarily for
remotely linked participants.We have not dealt with questions of telepresence
in this paper, but clearly the design of interaction spaces will extend
across more than one physical Some researchers have explored the use of
multi-device environments (e.g, [Agarwala 1997, Bier 1991, Rekimoto 1998,
Weiser 1991]).The issues in coordinating multiple activities at any degree
of co-presence are both technical and social, and as we expand the space
of possible participant-device configurations, we need to better understand
and design the ways that people work together.
Standard models
Today's GUI systems have a relatively mature and stable model for objects,
windows, menus, etc. This makes possible the ease of programming mentioned
in our scenarios. There are no corresponding models for human physical
activities, such as speech, gesture, and freehand drawing. These will be
more complex to develop, since they need to deal with inputs that can be
ambiguous and uncertain, and to fuse information from multiple modalities.
We expect models to emerge in the research, and to evolve through experience
to become sufficiently general.
6. CONCLUSION
This paper has proposed a conceptual framework for the design of interactive
computing environments based on a human-centered perspective. It would
take an ambitious effort to develop a general-utility system in accordance
with this perspective, and some of the key research problems were outlined.
There are several shorter-term actions that can be effective in solving
some of the problems that motivated the approach presented here.
First, in building new systems that implement parts of a general mechanism,
we can use structures that are compatible with the larger architecture
and open to extension within the framework. In our own work on the interactive
workspace, we plan to take this approach. We will develop and integrate
capabilities using a bottom-up strategy, with the larger-scale view as
background. Second, the conceptual distinctions here can be useful in sorting
out problems and confusions in designing special purpose systems. This
will become increasingly important as more applications begin to make use
of broad, rich input devices (e.g., cameras and microphones), with their
attendant problems of identification and context-based interpretation of
the phenomena of relevance to the user and computing system. Finally a
shift of perspective may be a catalyst to help provoke new ideas about
what to try, and what can be done in improving the ways in which computers
and people interact.
ACKNOWLEDGMENTS
Thanks to Michelle Baldonado, Henry Berg, François Gumbretiere,
and Debby Hindus for helpful comments on earlier drafts. Also to Pat Hanrahan
and the students in the Interactive Workspace project, for discussions
and an environment that raises the right questions.
REFERENCES
-
Agrawala. Maneesh, Andrew C. Beers, Bernd Fröhlich, Pat Hanrahan,
Ian MacDowall, and Mark Bolas, The Two-User Responsive Workbench: Support
for Collaboration Through Individual Views of a Shared Space, in Computer
Graphics Proceedings, SIGGRAPH 97. 1997, ACM: New York, NY, USA. p.
327-32.
-
Bederson, Ben. and J.D. Hollan, Pad++: a zooming graphical interface
for exploring alternate interface physics, in UIST 94. Seventh Annual
Symposium on User Interface Software and Technology. Proceedings of the
ACM Symposium on User Interface Software and Technology. 1994, ACM:
New York, NY, USA. p. 17-26.
-
Bederson, Ben, and Jon Meyer (1998), implementing a Zooming User Interface:
Experience Building Pad++, Software Practice and Experience, 1998
(in press).
-
Bier, Eric, and S. Freeman (1991), MMM: A User Interface Architecture for
Shared Editors on a Single Screen, UIST'91, 79-86.
-
Bolt, R.A, Put-That-There: Voice and Gesture at the Graphics Interface,
ACM SIGRAPH Comput. Graph. 14::3 262-270, 1980.
-
Buxton, W. (1997). Living in Augmented Reality: Ubiquitous Media and Reactive
Environments. In K. Finn, A. Sellen & S. Wilber (Eds.). Video Mediated
Communication. Hillsdale, N.J.: Erlbaum, 363-384. An earlier version
of this chapter also appears in Proceedings of Imagina '95, 215-229.
-
Engler, Dawson, M. Frans Kaashoek, and James O'Toole, Jr. (1995), Exokernel:
An Operating System Architecture for Application-Level Resource Management,
Proceedings of the Fifteenth Symposium on Operating Systems Principles,
December 1995, 1-16.
-
Fitzmaurice, George, Hiroshi Ishii, and William Buxton (1995), Bricks:
Laying the Foundations for Graspable User Interfaces. CHI'95, 442-449,
1995.
-
Gibson, James. The Ecological Approach to Visual Perception. New
York: Houghton Mifflin, 1979.
-
Ishii, Hiroshi and Brygg Ullmer (1997), Tangible Bits: Towards Seamless
Interfaces between People, Bits, and Atoms, CHI'97, 234-241.
-
Lucente, Mark, Gert-Jan Zwart, and Andrew George (1998), Visualization
Space: A Testbed for Deviceless Multimodal User Interface, Intelligent
Environments Symposium, AAAI Spring Symposium, 1998.
-
Maes, Patti, Trevor Darrell, Bruce Blumberg, and Alex Pentland (1993),
ALIVE: Artificial Life Interactive Video Environment, Visual proceedings
of SIGGRAPH'93.
-
Massalin, Henry, and Calton Pu (1989), Threads and Input/Output in the
Synthesis Kernel, Proceedings of the 12th ACM Symposium on Operating
Systems Principles, 1989, 191-201.
-
Matsushita, Nobuyuki and Jun Rekimoto (1997), HoloWall: Designing a Finger,
Hand, Body, and Object Sensitive Wall, UIST'97, 209-210.
-
McCanne, Steven et al. (1997), Toward a Common Infrastructure for Multimedia-Networking
Middleware, Proc. 7th Intl. Workshop on Network and Operating Systems
Support for Digital Audio and Video, May, 1997.
-
Moran, Thomas, Patrick Chiu, and William van Melle (1997), Pen-based Interaction
Techniques for Organizing Material on an Electronic Whiteboard, UIST'97,
45-54.
-
Myers, Brad A, Herb Stiel, and Robert Gargiulo. "Collaboration Using Multiple
PDAs Connected to a PC.'' Proceedings CSCW'98: ACM Conference on Computer-Supported
Cooperative Work, November 14-18, 1998, Seattle, WA. 285-294.
-
Norman. DA, The Invisible Computer, Cambridge, MA: MIT Press, 1998.
-
Pederson, E.R., et al., Tivoli: an electronic whiteboard for
informal workgroup meetings, in Human Factors in Computing Systems.
INTERCHI '93. 1993, IOS Press: Amsterdam, Netherlands. p. 391-8.
-
Powers, William T. (1973). Behavior: The Control of Perception.
Hawthorne, NY: Aldine DeGruyter
-
Rekimoto, Jun (1998), A Multiple Device Approach for Supporting Whiteboard-based
Interactions, CHI'98, 344-351.
-
Rekimoto, J., Multiple-computer user interfaces: a cooperative environment
consisting of multiple digital devices, in Cooperative Buildings.
Integrating Information, Organization, and Architecture. First International
Workshop, CoBuild'98 Proceedings, N.A. Streitz, S. Konomi, and H.J.
Burkhardt, Editors. 1998, Springer-Verlag: Berlin, Germany. p. 33-40
-
Robertson, George, Stuart Card, and Jock Mackinlay (1989), The cognitive
coprocessor architecture for interactive user interfaces, UIST'89,
10-18.
-
Streitz, N., Konomi, S., Burkhardt, H.-J. (Eds.) (1998), Cooperative
Buildings - Integrating Information, Organization, and Architecture.
Proceedings of CoBuild'98. Darmstadt, February 1998. Lecture Notes
in Computer Science 1370. Springer: Heidelberg, 1998.
-
Streitz, Norbert, J. Geißler, T. Holmer (1998), Roomware for Cooperative
Buildings: Integrated Design of Architectural Spaces and Information Spaces,
Proceedings of CoBuild'98. Darmstadt, February 1998.
-
Ullmer, Brygg, Hiroshi Ishii, and Dylan Glas (1998), mediaBlocks: Physical
Containers, Transports, and Controls for Online Media, SIGGRAPH'98.
-
Weiser, Mark (1991), The Computer for the Twenty-first Century, Scientific
American 265:3, 1991, 94-104.